Golang 中 Slice 实现及源码分析
数组
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整形、字符串或者自定义类型。
数组元素可以通过索引(位置)来读取(或者修改),数组一旦定义后,大小不能更改。
数组是值类型。
1var variable_name [SIZE] variable_type
2
3var arr = [5] int{'A', 'B', 'C', 'D', 'E'}
4
5// 表示 arr[4] 和 arr[9] 初始化为1,会根据最后一个 9:1 来判断数组大小为 10
6var arr = [...]int{4:1, 9:1}
7
8// 多维数组
9arr := [3][2]int{
10 {1,2},
11 {3,4},
12 {5,6}, //需要逗号
13}
Slice
数组固定长度也限制了数组的使用,长度甚至是类型的一部分,[3]int 和 [4]int 是两种不同的类型。内置切片即动态数组,使用很方便,本身不包含任何数据,只是对现有数组的引用。
数据结构
1// runtime/slice.go
2type slice struct {
3 array unsafe.Pointer // 元素指针
4 len int // 长度
5 cap int // 容量
6}

slice 是引用类型:slice 本身是一个结构体,但它包含一个指向底层数组的指针,因此多个 slice 可以共享同一个底层数组。修改其中一个 slice 的元素可能会影响其他 slice。
初始化
1arr[0:3] or slice[0:3] // 通过下标的方式获得数组或者切片的一部分
2slice := []int{1, 2, 3} // 使用字面量初始化新的切片
3slice := make([]int, 10) // 使用关键字 make 创建切片
1package main
2
3import "fmt"
4
5func main() {
6 slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
7 s1 := slice[2:5]
8 s2 := s1[2:6:7]
9
10 s2 = append(s2, 100)
11 s2 = append(s2, 200)
12
13 s1[2] = 20
14
15 fmt.Println(s1)
16 fmt.Println(s2)
17 fmt.Println(slice)
18}
传参陷阱
1func main() {
2 sl := make([]int, 0, 0)
3 test(sl)
4 fmt.Println(len(sl)) // 0
5}
6
7func test(sl []int) {
8 sl = append(sl, 1)
9}
原因是初始创建的 slice 容量是0,插入一个元素后会触发扩容,扩容会返回新的 slice。而 golang 是值传递,传入原 slice 的副本,副本指向的是原 array,扩容后导致副本指向新的 array,然后在新的 array 中添加新元素,因此不会影响到原 slice,外部的 slice 长度仍然是 0。
解决方法自然是直接传 slice 的指针。
1func main() {
2 sl := make([]int, 0, 0)
3 test(&sl)
4 fmt.Println(len(sl)) // 1
5}
6
7func test(sl *[]int) {
8 sl = append(sl, 1)
9}
操作
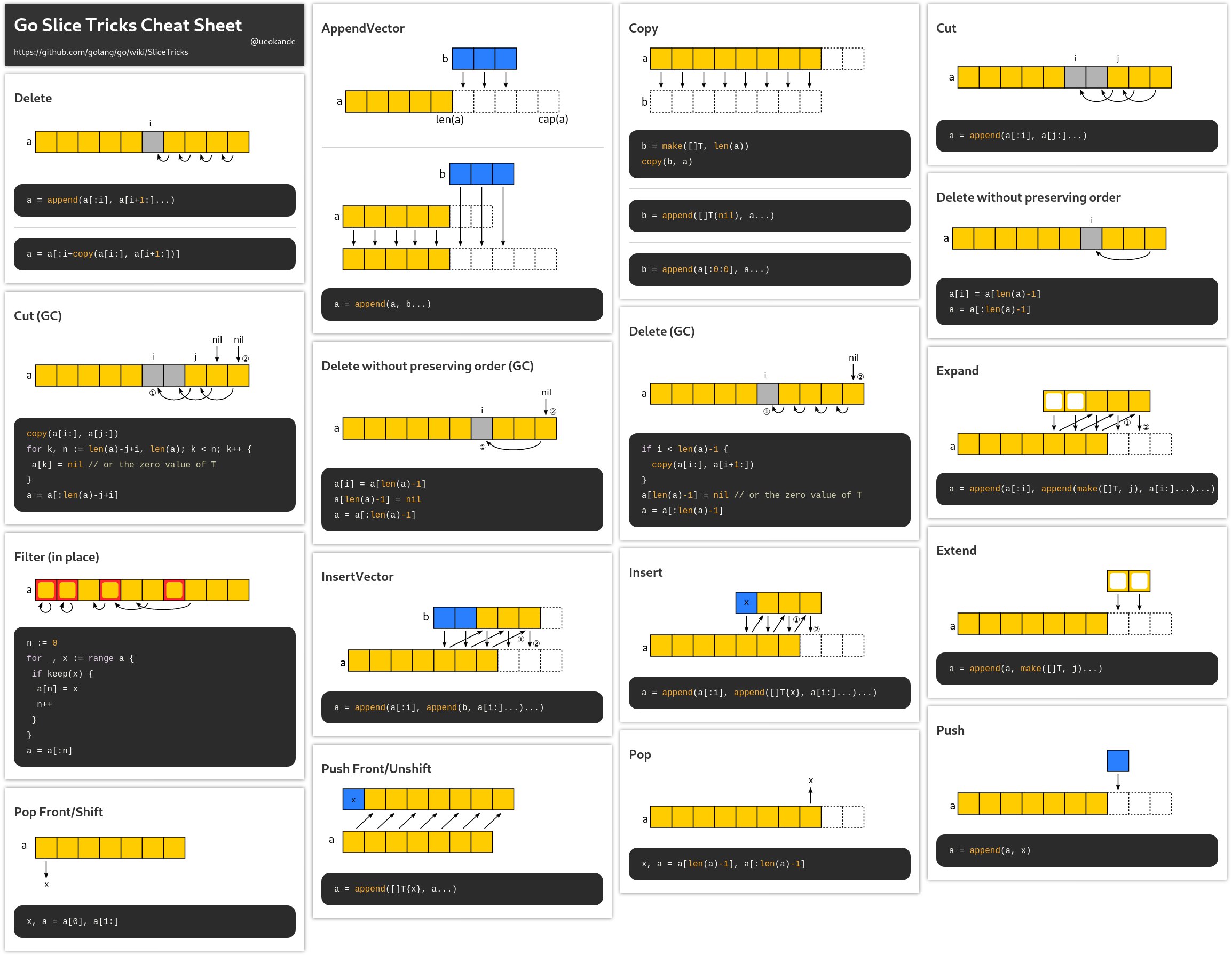
官方 wiki - SliceTricks 介绍了切片常见的操作技巧。
性能陷阱
内存泄漏
- 陷阱:对一个大 slice 进行切片操作后保留小部分,但底层数组仍然被引用,导致整个大数组无法被回收。
- 方案:显式拷贝需要的部分。
1// bad
2func getLastElement() []byte {
3 largeSlice := make([]byte, 1<<20) // 1MB
4 return largeSlice[len(largeSlice)-10:] // 只返回最后10个字节
5 // 但整个1MB的数组仍然被保留
6}
7
8// good
9func getLastElement() []byte {
10 largeSlice := make([]byte, 1<<20)
11 last10 := make([]byte, 10)
12 copy(last10, largeSlice[len(largeSlice)-10:])
13 return last10
14}
频繁扩容
- 陷阱:不断追加元素导致 slice 频繁扩容,引发多次内存分配和数据拷贝。
- 方案:预分配足够容量
1// bad
2var s []int
3for i := 0; i < 1000000; i++ {
4 s = append(s, i) // 可能导致多次扩容
5}
6
7// good
8s := make([]int, 0, 1000000) // 一次性分配足够容量
9for i := 0; i < 1000000; i++ {
10 s = append(s, i)
11}
特别的,不仅是创建时,在操作时也可以扩容,func slices.Grow*S* ~[]E, *E* any*s* S, *n* int S。
注意,分配内存本身是要付出性能的代价的,不是以下两种场景时预分配都会不可避免的产生大量浪费,这些浪费带来的性能代价很可能会超过扩容的代价。
- 明确知道slice里会有多少个元素的场景
- 元素的个数虽然不确定,但大致在
[x, y]的区间内,这时候可以选择设置预分配大小为y+N(N取决于误差范围,预分配大量内存之后再触发扩容的代价非常高昂,所以算好误差范围宁可少量浪费也要避免再次扩容),当然x和y之间的差不能太大,像1和1000这种很明显是不应该进行预分配的,主要的判断依据是最坏情况下的内存浪费率。
经典
1package main
2
3import "fmt"
4
5func main() {
6 slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
7 s1 := slice[2:5]
8 s2 := s1[2:6:7]
9
10 s2 = append(s2, 100)
11 s2 = append(s2, 200)
12
13 s1[2] = 20
14
15 fmt.Println(s1)
16 fmt.Println(s2)
17 fmt.Println(slice)
18}
s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。 s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。
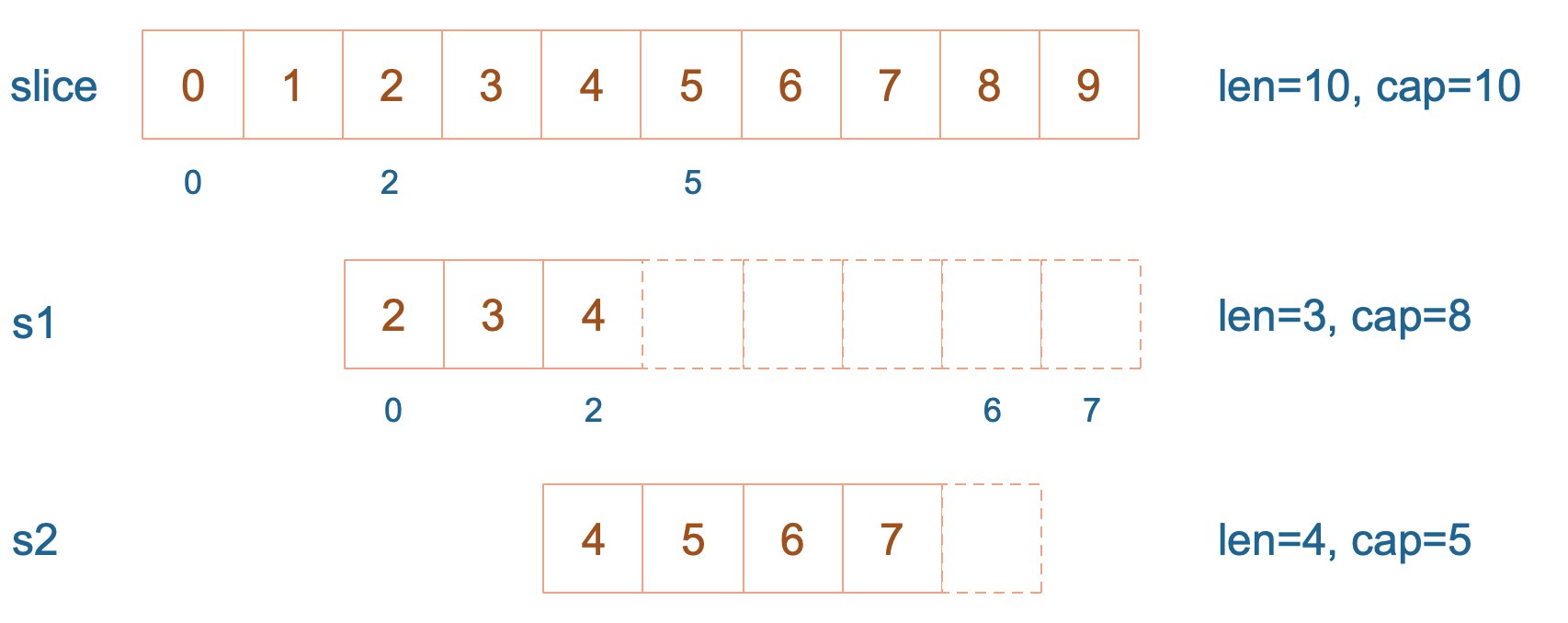
接着,向 s2 尾部追加一个元素 100,s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。
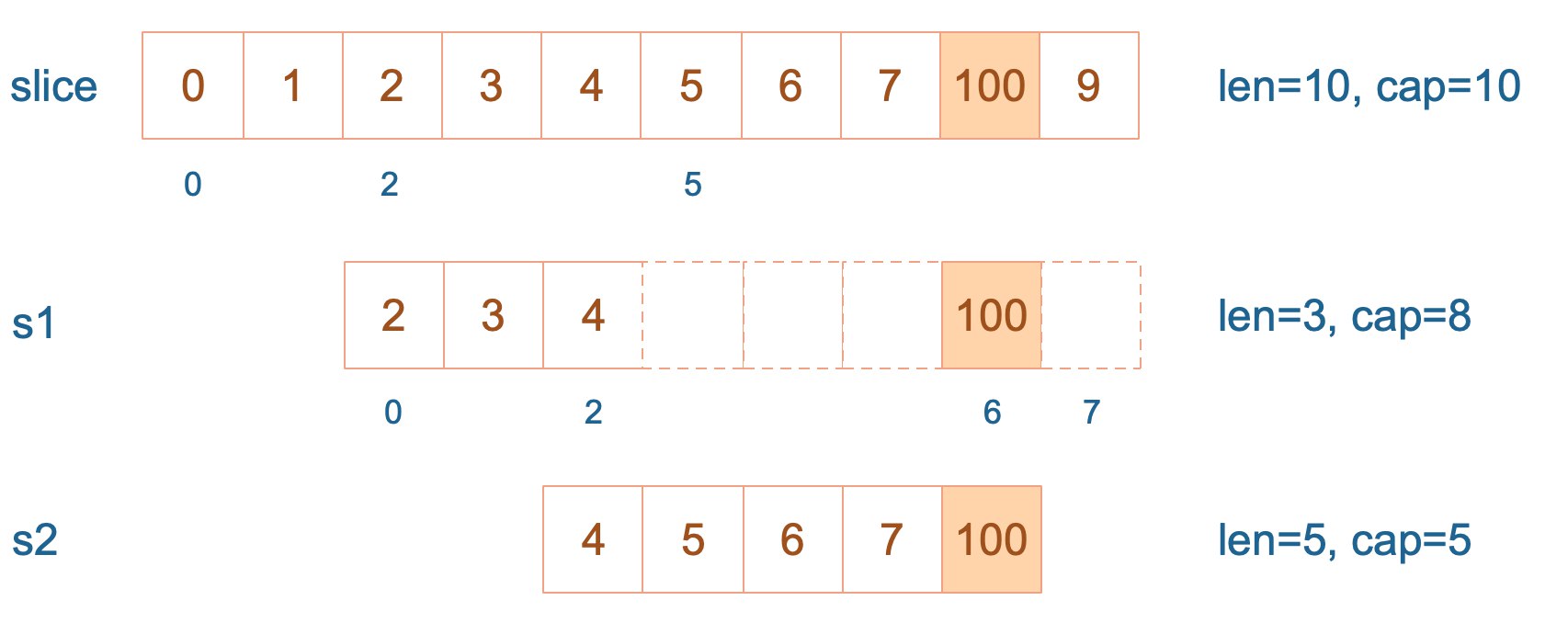
再次向 s2 追加元素200,这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。
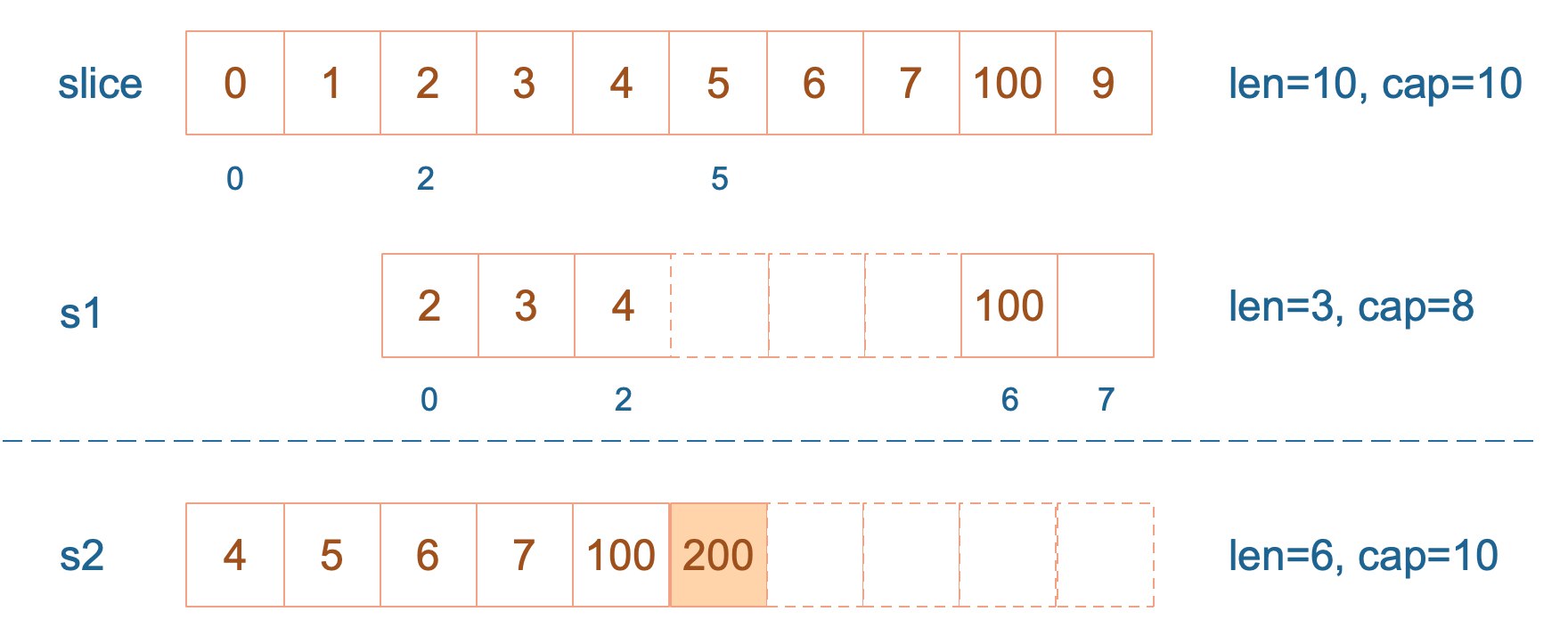
最后,修改 s1 索引为2位置的元素,这次只会影响原始数组相应位置的元素。它影响不到 s2 了,人家已经远走高飞了。
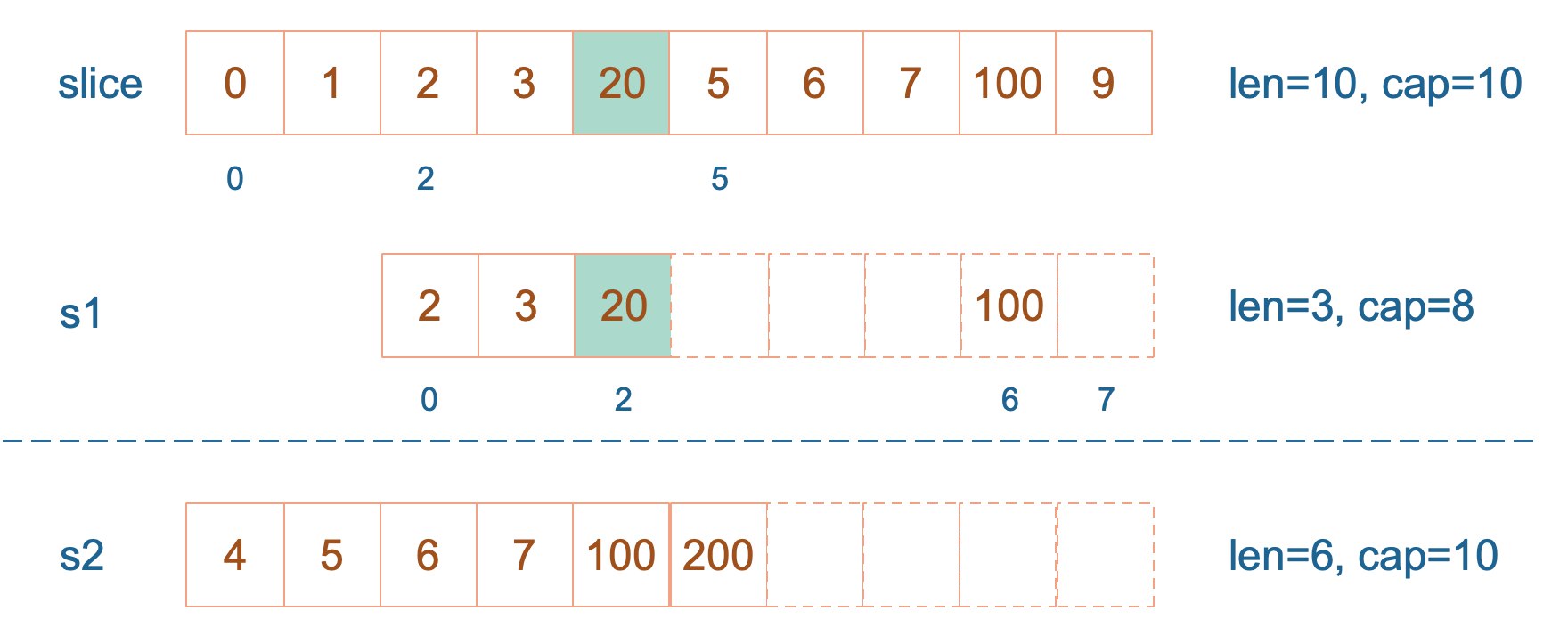
最终答案为:
1[2 3 20]
2[4 5 6 7 100 200]
3[0 1 2 3 20 5 6 7 100 9]
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。